Albedo to EARS, Pt. 7 - Final Results
Happy National Pet Day! Pet your cat if you have one. Last time I got all the pieces in place to perform ADRRS and EARS - the scene tracer, the scene integrator, the spatial cache, and the local and global statistical accumulators. The RRS values that were being produced were too strong, so I spent the last two weeks combing through to find where things were going awry. I’m happy to say that I found them! In this post I’ll discuss my process for diagnosing and fixing the ADRRS and EARS algorithms. Last thing’s first, here’s the final results:

Project proposal: project-proposal.pdf
First post in the series: Directed Research at USC
GitHub repository: roblesch/roulette
Bug Bashing
Here’s where things left off:

Clearly this isn’t right. The first 3 iterations are the training iterations - these use classic albedo-based RRS. The fourth iteration is the first which uses EARS, and right away things are going wrong. The RR likelihood is far too high, and on each iteration this error compounds until there is little to no information collected at all in regions where work should be emphasized.
I did a pass on some known issues - the integrator was refactored to render the image in 32x32 blocks (default block size in Mitsuba) and to accumulate image statistics block-wise. I fixed a bug in the tracer where results were being cached even when no samples were collected on that path segment. I updated the scene to add an obscuring panel to create more difficult paths which should make the contributions of ADRRS and EARS more apparent.

This is an improvement over the above. The leftmost image is the last training iteration, performed with classic RRS. Iterations 4-6 are using EARS. It looks like RRS is no longer diverging quite as aggressively, but it’s still not doing the right thing - the region under the panel should be showing more work performed under EARS via splitting, but it looks like rays are being culled even more often than with classic RRS.
Examining the Cache
I had a tip on my last post from Sebastian Herholz, an engineer at Intel and co-author on EARS. He observed that the RRS was too aggressive and suggested using ADRRS as a means of validating the cache since ADRRS uses only the Lr estimate as its adjoint.
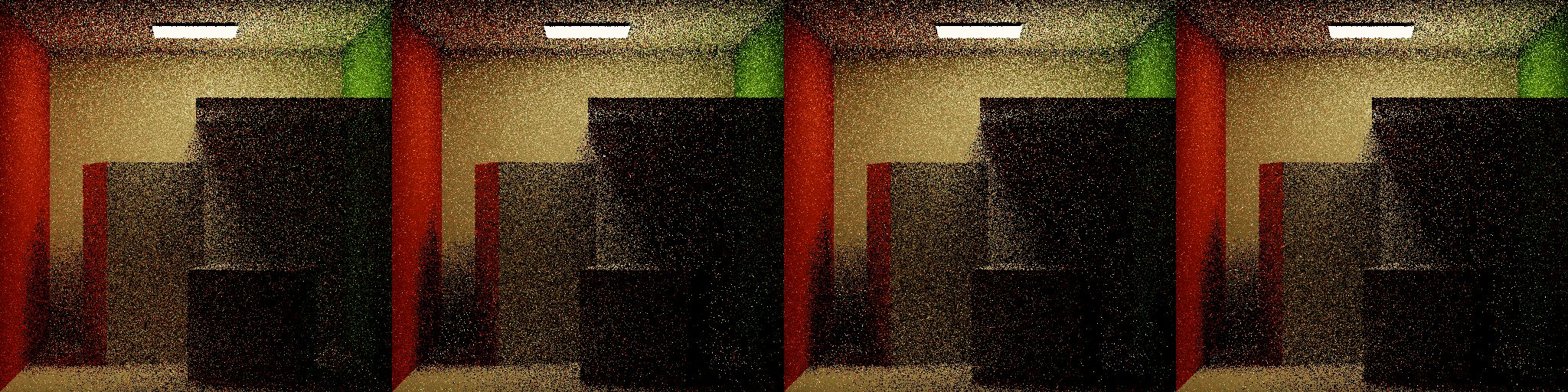
With ADRRS the same issue occurrs - too aggressive RR - but this narrows the issue down to something with the cache. I combed through the cache implementation and found no issues - maybe I was collecting too few samples? I spent quite awhile rendering at higher resolutions, more samples per pixel… quite a painful task in a single-threaded CPU renderer. The number of samples in the cache didn’t seem to have any effect. Maybe I made a mistake in mapping intersections to the cache? After a lot of going in circles, I decided to draw the results of querying the Lr cache. These images are generated by tracing rays into the scene and returning the Lr estimate at the first intersection.

Though not the prettiest thing to look at, it does seem like the cache is doing the right thing. It visibly subdivides over each iteration, correctly maps intersections to the unit cube, and seems to be storing a reasonable approximation of Lr in each bin. Regions in black indicate nodes that haven’t collected enough samples for training, which is appropriately handled in the RR evaluation.
The Actual Issue
Running out of options, I resorted to combing through the code and comparing it to the original implementation to see if anything was broken or missing. Eventually I found that I was missing this -
1
2
if (!m_currentRRSMethod.useAbsoluteThroughput)
input.weight /= pixelEstimate + Spectrum { 1e-2 };
When creating a new primary ray, if the current iteration uses a learning-based method (ADRRS, EARS) the initial weight (throughput) is initialized as the inverse of the current image estimate (denoised merge image over all iterations) plus some normalizing lower-bound. And of course, this was the issue all along.
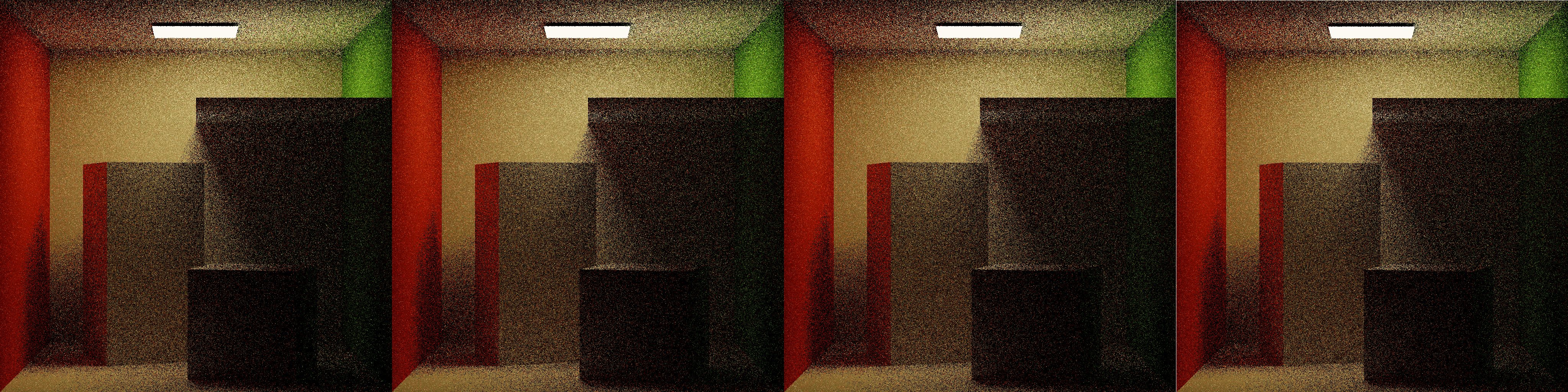
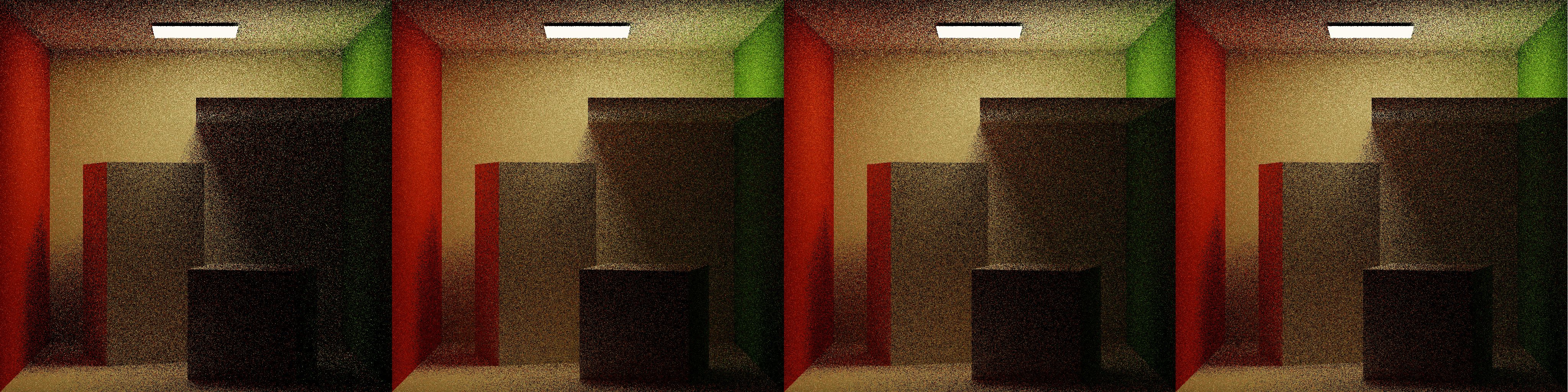
With this change, ADRRS and EARS both perform visibly more work in regions with difficult lighting, under the panel, the shadow between the cube and the wall. EARS especially ramps the splitting dramatically in difficult regions before backing off over more iterations.
Technique Comparisons
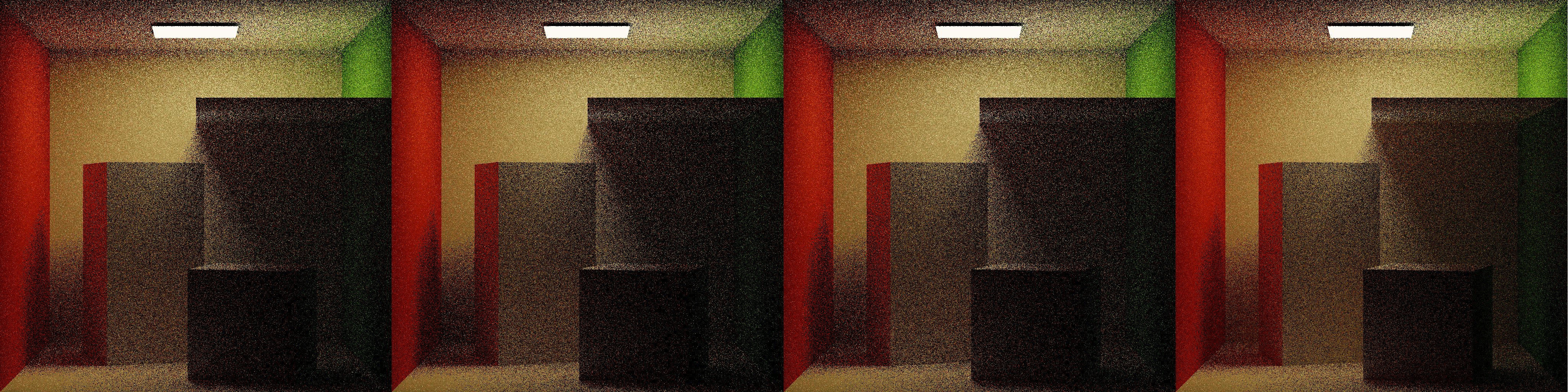
Shown above are 1 iteration of NoRR, ClassicRR, ADRRS, and EARS, each at 1spp. In ClassicRR, difficult lighting regions are overly punished due to their low throughput. In the same regions under the panel, ADRRS and EARS both emphasize work by performing splitting to gather more information, with EARS creating the most emphasis.

After 16 iterations, ADRRS and EARS both show improvements over NoRR and ClassicRR in the difficult regions under the panel, with EARS showing the greatest improvement.
Closing thoughts
Thank you for following along over the last 15+ weeks. This was my first experience working with a learning-based technique in light transport estimation, and wrapping my head around the various added pieces was quite an undertaking. EARS is a compelling example of integrating leveraging a learning-based framework like Intel’s OIDN to improve some of the foundational operations in path tracing like Russian Roulette & Splitting. I’m excited to see what else is in store. If you enjoyed reading these, stay tuned for more - I’ll always have something in the works!